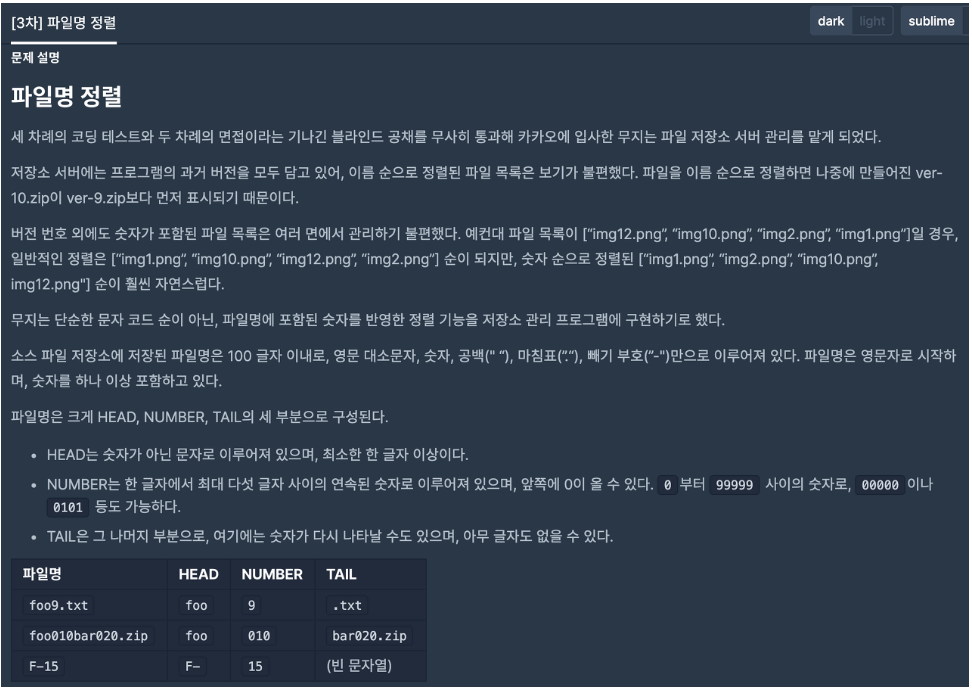
이진 트리 : 이진 트리의 순회는 재귀 호출을 사용한다. 따라서 전위, 중위, 후위 순회를 간단하게 구현할 수 있다. 순회란 모든 원소를 빠트리거나 중복하지 않고 처리하는 연산을 의미한다.
class Node:
def __init__(self, data):
self.data = data
self.left = None
self.right = None
def __str__(self):
return str(self.data)
class Tree:
def __init__(self):
self.root = None
def preorderTraversal(self, node):
print(node, end='')
if not node.left == None : self.preorderTraversal(node.left)
if not node.right == None : self.preorderTraversal(node.right)
def inorderTraversal(self, node):
if not node.left == None : self.inorderTraversal(node.left)
print(node, end='')
if not node.right == None : self.inorderTraversal(node.right)
def postorderTraversal(self, node):
if not node.left == None : self.postorderTraversal(node.left)
if not node.right == None : self.postorderTraversal(node.right)
print(node, end='')
def makeRoot(self, node, left_node, right_node):
if self.root == None:
self.root = node
node.left = left_node
node.right = right_node
if __name__ == "__main__":
node = []
node.append(Node('-'))
node.append(Node('*'))
node.append(Node('/'))
node.append(Node('A'))
node.append(Node('B'))
node.append(Node('C'))
node.append(Node('D'))
m_tree = Tree()
for i in range(int(len(node)/2)):
m_tree.makeRoot(node[i],node[i*2+1],node[i*2+2])
print( '전위 순회 : ', end='') ; m_tree.preorderTraversal(m_tree.root)
print('\n' + '중위 순회 : ', end='') ; m_tree.inorderTraversal(m_tree.root)
print('\n' + '후위 순회 : ', end='') ; m_tree.postorderTraversal(m_tree.root)전위 순회
전위 순회는 DLR 순서로 순회한다.
- D : 현재 노드를 출력한다
- L : 현재 노드 왼쪽 서브트리로 이동한다
- R : 현재 노드 오른쪽 서브트리로 이동한다
def preorderTraversal(self, node):
print(node, end='')
if not node.left == None : self.preorderTraversal(node.left)
if not node.right == None : self.preorderTraversal(node.right)해당 노드를 출력하고 왼쪽으로 이동한다. 왼쪽 노드가 존재하면 계속해서 왼쪽으로 이동하여 출력하고 왼쪽이 끝나는 노드부터 오른쪽 노드를 순회한다.
중위 순회
중위 순회는 LDR 순서로 순회한다. 왼쪽 순회가 우선이고 출력이 중앙에 위치한다.
def inorderTraversal(self, node):
if not node.left == None : self.inorderTraversal(node.left)
print(node, end='')
if not node.right == None : self.inorderTraversal(node.right)후위 순회
후위 순회는 LRD로 순회한다. 출력이 마지막에 위치한다.
def postorderTraversal(self, node):
if not node.left == None : self.postorderTraversal(node.left)
if not node.right == None : self.postorderTraversal(node.right)
print(node, end='')
예시
프로그래머스 길 찾기 게임
https://programmers.co.kr/learn/courses/30/lessons/42892
코딩테스트 연습 - 길 찾기 게임
[[5,3],[11,5],[13,3],[3,5],[6,1],[1,3],[8,6],[7,2],[2,2]] [[7,4,6,9,1,8,5,2,3],[9,6,5,8,1,4,3,2,7]]
programmers.co.kr
class Node:
def __init__(self, x, key):
self.x = x
self.key = key
self.left = None
self.right = None
class Tree:
def __init__(self):
self.head = None
self.pre_result = list()
self.post_result = list()
def insert(self, x, key):
current_node = self.head
if self.head is None:
self.head = Node(x, key)
else:
while True:
if current_node.x > x:
if current_node.left:
current_node = current_node.left
else:
current_node.left = Node(x, key)
break
else:
if current_node.right:
current_node = current_node.right
else:
current_node.right = Node(x, key)
break
def preorder(self):
def _preorder(root):
if root is None:
pass
else:
self.pre_result.append(root.key)
_preorder(root.left)
_preorder(root.right)
_preorder(self.head)
def postorder(self):
def _postorder(root):
if root is None:
pass
else:
_postorder(root.left)
_postorder(root.right)
self.post_result.append(root.key)
_postorder(self.head)
import sys
sys.setrecursionlimit(10**6)
def solution(nodeinfo):
tmp = nodeinfo
tmp = sorted(tmp, key=lambda x: x[1], reverse=True)
T = Tree()
for i in range(len(nodeinfo)):
T.insert(tmp[i][0], nodeinfo.index(tmp[i]) + 1)
T.preorder()
T.postorder()
answer = [T.pre_result, T.post_result]
return answer메인 함수는 solution(nodeinfo)이다. (nodeinfo.index(tmp[i])+1 에서 1을 더하는 이유는 문제에서 노드가 1부터 시작하기 때문이다.)
알고리즘
1. nodeinfo를 y의 값을 기준으로 sorting해서 tmp에 담아준다.
2. T라는 객체를 만든다.
3. sorting한 tmp에서 0부터 len(nodeinfo)까지 T.insert를 반복한다.
4. T.preorder()를 한다.(전위순회하면서 pre_result에 key를 저장)
5. T.postorder()를 한다.(후위순회하면서 post_result에 key를 저장)
6. answer에 pre_result와 post_result를 저장하고 return한다.
※T.insert()에 대한 설명
가장 처음에 insert()할 때, self.head = None이다. 따라서 self.head = Node(x, key)를 수행한다.
나중에 insert()할 때, While문으로 들어간다.
class Node:
def __init__(self, x, key):
self.x = x
self.key = key
self.left = None
self.right = None
class Tree:
....
def insert(self, x, key):
current_node = self.head
if self.head is None:
self.head = Node(x, key)
....
while True:
if current_node.x > x:
if current_node.left:
current_node = current_node.left
else:
current_node.left = Node(x, key)
break
else:
if current_node.right:
current_node = current_node.right
else:
current_node.right = Node(x, key)
breakwhile문에서
현재의 node의 x값이 insert할 x값보다 클 때, 현재 node의 left에 무엇인가 담겨있다면 현재의 node에 현재의 node 왼쪽값을 담는다.(왼쪽 아래로 비어있을 때까지 이동) // 현재 node의 left가 비어있다면 insert할 Node(x, key)를 넣어주고 break한다.
현재의 node의 x값이 insert할 x값보다 작을 때, 현재 node의 오른쪽에 무엇인가 담겨있다면 현재의 node에 현재의 node 오른쪽값을 담는다.(오른쪽 아래로 비어있을 때까지 이동) // 현재 node의 오른쪽이 비어있다면 insert할 Node(x,key)를 넣어주고 break한다.
'데이터사이언스' 카테고리의 다른 글
| 파이썬 입력받기 (0) | 2022.03.03 |
|---|---|
| 파이썬 문자열 압축(feat. 프로그래머스 문자열 압축 문제) (0) | 2020.05.29 |
| 파이썬 1개의 row List 여러개의 열로 자르기 (0) | 2020.05.20 |
| 파이썬 N진수 변환 알고리즘 (0) | 2020.05.20 |
| 캐시(Cache) : 프로그래머스 문제를 예제로 (0) | 2020.05.19 |